Abstract
Results
Crush
Method Overview
Background
Existing REPA aligns the hidden states of Image Diffusion Transformers with pretrained visual features, improving convergence and generation quality. When REPA is applied to Video Diffusion Models (VDMs) as REPA*, it performs frame-wise alignment but fails to maintain semantic consistency across frames. Due to the inherent nature of denoising autoencoders (DAEs), hidden states extracted from noisy inputs can vary stochastically across frames, leading to semantic misalignment between adjacent frames.
Motivation from Empirical Observation
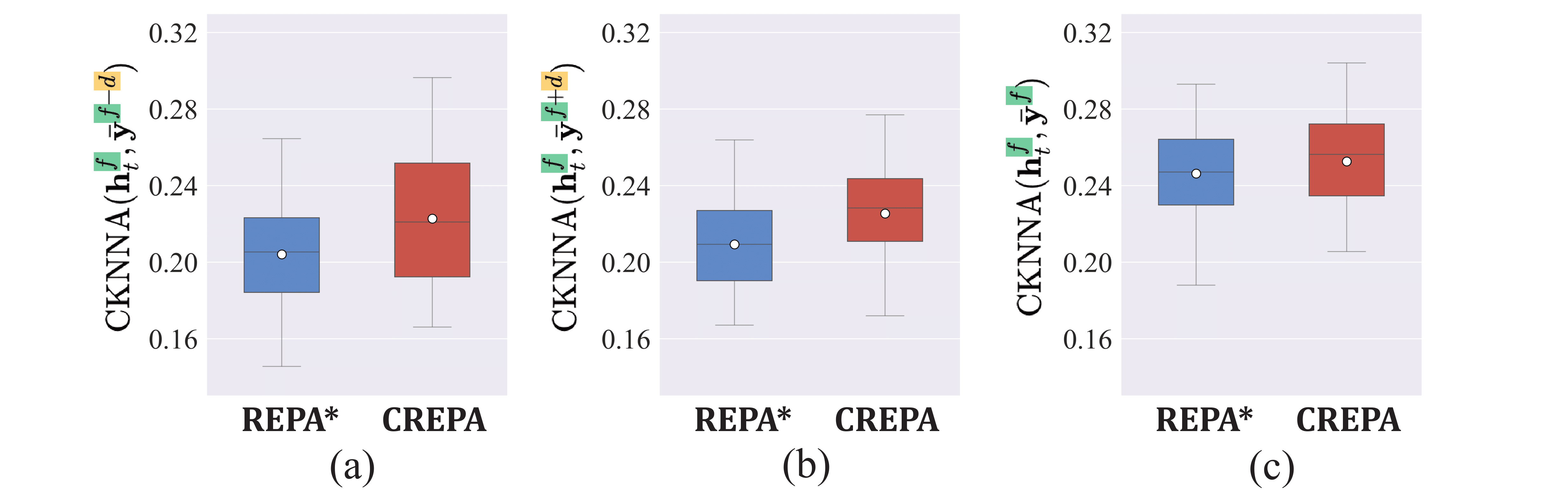
The motivation for Cross-frame Representation Alignment (CREPA) stems from empirical observations regarding the behavior of hidden states in Video Diffusion Models (VDMs). As shown in the figure below, we visualize the learned hidden states using CKNN-A (Continuous K-Nearest Neighbors Alignment) on pretrained feature manifolds. Under REPA*, the hidden states exhibit stochastic drifts and fail to follow a smooth trajectory across frames. In contrast, with CREPA, the hidden states more faithfully align with the pretrained feature manifold, leading to improved temporal semantic consistency and smoother cross-frame representations. This empirical observation supports our design choice to explicitly align hidden states with neighboring frames during fine-tuning.
Core Idea of CREPA
CREPA explicitly aligns the hidden state of each frame with both its own pretrained feature and the features of adjacent frames. This encourages the hidden states to remain smooth and consistent along a temporal semantic manifold, improving cross-frame semantic consistency in generated videos.
Implementation
REPA*
- For each frame \( f \):
- Clean frame → pretrained encoder → pretrained feature \( \bar{y}^f \)
- Noisy input → DiT encoder → hidden state \( h_t \), per-frame hidden state \( h^f_t \)
- Project \( h^f_t \) via MLP → alignment loss:
$$ \mathcal{L}_{align} = - \mathbb{E}_{x_0, \epsilon, t} \left[ \sum_f \text{sim}(\bar{y}^f, h_\phi(h^f_t)) \right] $$
Final objective:
$$ \mathcal{L} = \mathcal{L}_{score} + \lambda \mathcal{L}_{align} $$
CREPA
- Adds alignment with pretrained features of adjacent frames:
$$ \mathcal{L}_{align} = - \mathbb{E}_{x_0, \epsilon, t} \left[ \sum_f \left( \text{sim}(\bar{y}^f, h_\phi(h^f_t)) + \sum_{k \in K} e^{-\frac{|k-f|}{\tau}} \cdot \text{sim}(\bar{y}^k, h_\phi(h^f_t)) \right) \right] $$
Key Features
- Simple and effective distillation-based regularization
- Improves both cross-frame semantic consistency
- Easily integrable into existing fine-tuning pipelines
- Outperforms REPA* and vanilla fine-tuning across various datasets and metrics
BibTeX
@misc{hwang2025crepa,
title={Cross-Frame Representation Alignment for Fine-Tuning Video Diffusion Models},
author={Sungwon Hwang and Hyojin Jang and Kinam Kim and Minho Park and Jaegul choo},
year={2025},
eprint={2506.09229},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.09229},
}